
[V8 GC] Concurrent marking
이 포스트의 원문은 여기 임을 밝힙니다.
이 포스트에서는 concurrent marking 이라고 불리는 garbage collection 테크닉에 대해 소개합니다. 이를 통해 garbage collector가 heap에서 활성 객체를 찾고 마킹하기 위해 작업하는 동안, 자바스크립트 어플리케이션이 멈추지 않고 계속 실행될 수 있습니다. 벤치마킹을 통해서 concurrent marking이 메인 쓰레드에서 마킹하는데 드는 시간을 60% ~ 70% 감소시킨다는 것을 확인하였습니다. Concurrent marking은 Orinoco project의 마지막 퍼즐 조각입니다. (과거의 garbage collector를 점진적으로 concurrent, parallel한 garbage collector로 대체하고자 하는 프로젝트 입니다.)
배경
마킹(marking)은 V8의 Mark-Compact garbage collector의 한 과정입니다. 이 과정 동안 collector는 모든 활성 객체를 탐지하고, 마킹합니다. 마킹은 전역 객체와 현재 활동 중인 함수들과 같은 (이른바 “roots”), 알려진 활성 객체들의 집합으로부터 시작합니다. collector는 그 루트들을 활성화 되었다고 마킹하고, 그들이 가지고 있는 포인터들을 추적해서 더 많은 활성 객체들을 탐지합니다. collector는 더이상 마킹할 객체가 없을 때 까지 계속해서 새로 발견하는 객체들을 마킹하고, 포인터들을 추적합니다. 마킹을 다 진행한 뒤, heap 내에 마킹되지 않은 객체들이 있다면 이들은 모두 어플리케이션에서 도달할 수 없는 녀석들이고, 안전하게 수집될 수 있습니다.
마킹을 그래프 순회(graph traversal)로 생각할 수 있습니다. heap에 있는 객체들은 그래프의 노드들입니다. 한 객체에서 다른 객체로 이어지는 포인터들은 그래프에서 엣지에 해당합니다. 그래프에서 노드가 주어지면, 해당 노드의 밖으로 나아가는(out-going) 모든 엣지들을 그 객체의 hidden class를 통해 찾을 수 있습니다.
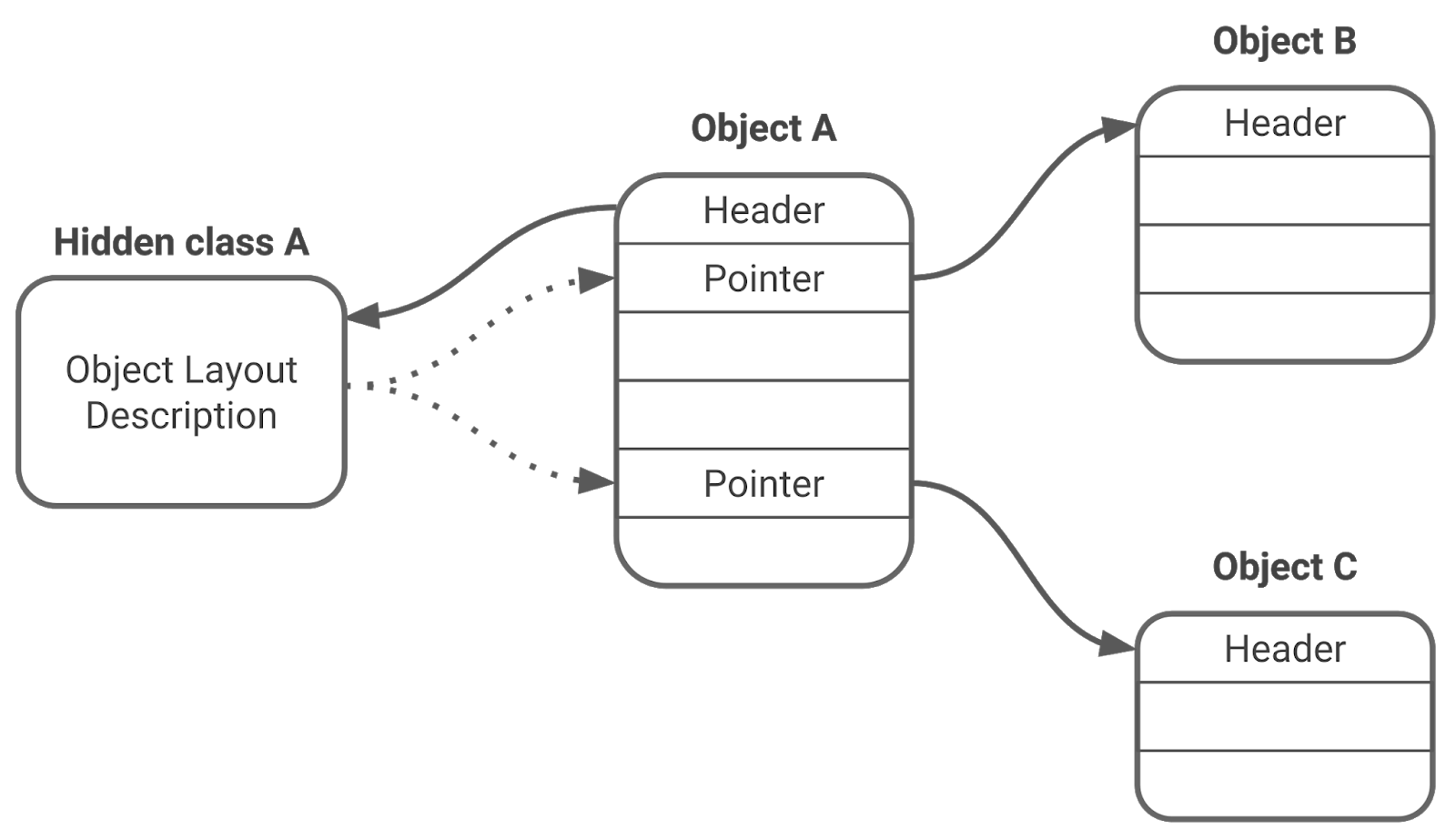 Figure 1. 객체 그래프
Figure 1. 객체 그래프
V8은 두 개의 mark-bit와 마킹 worklist를 통해 마킹을 구현합니다. 두 mark-bits는 세 가지 색깔로 인코드 됩니다: 흰색(00), 회색(10), 검정(11). 처음에 모든 객체들은 흰색입니다. 이는 아직 그들을 collector가 발견하지 못했음을 의미합니다. collector가 그들을 발견하고 marking worklist에 그들을 추가하면, 흰색 객체는 회색이 됩니다. 마지막으로 collector가 marking worklist에서 꺼내어 그것의 필드(fields)를 모두 방문하면 검정색이 됩니다. 이 스키마를 tri-color marking이라고 부릅니다. 마킹은 더이상 회색 객체가 없을 때 종료됩니다. 모든 남아있는 흰색 객체들은 도달할 수 없는 것이고, 안전하게 수집될 수 있습니다.
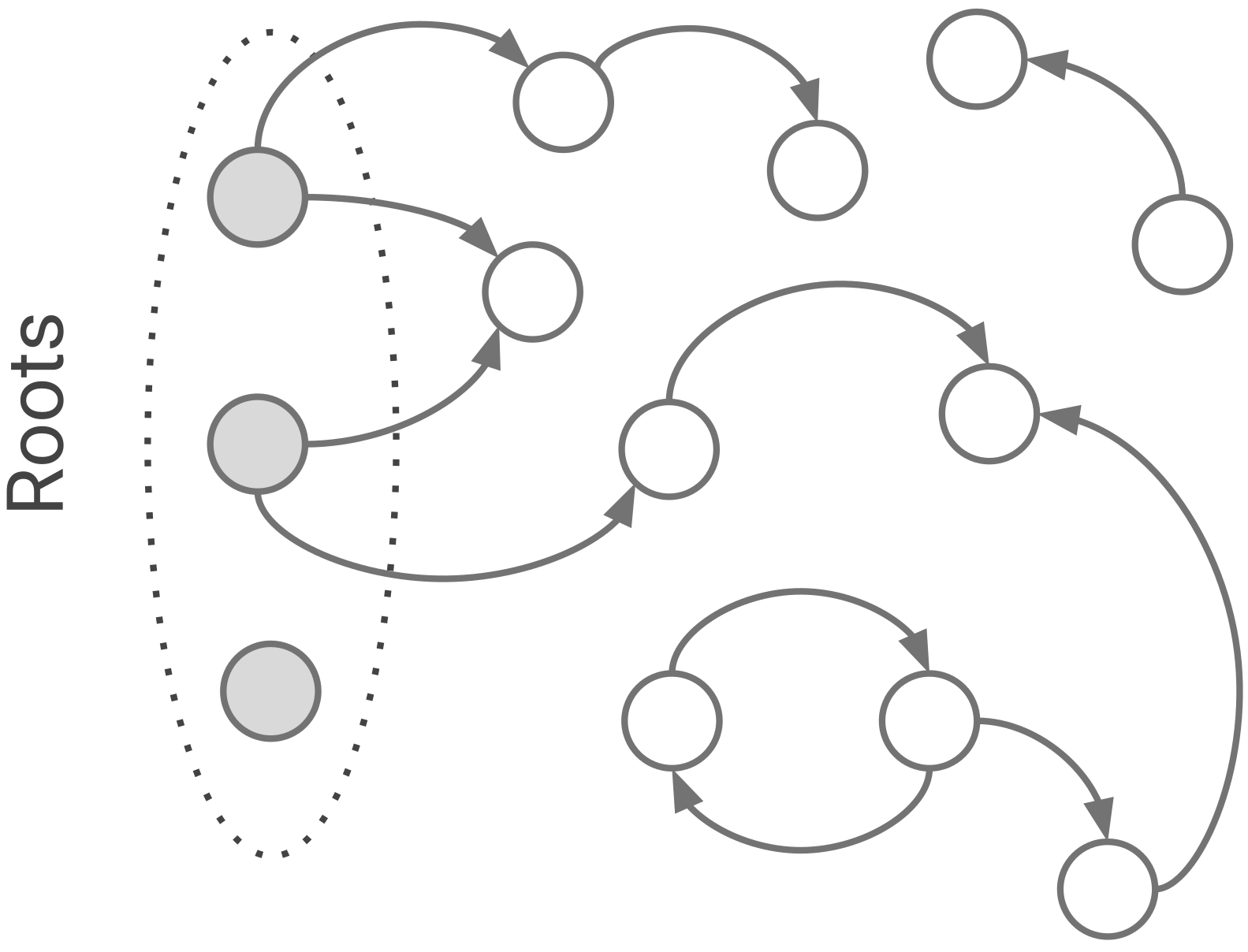 Figure 2. 마킹은 루트에서 시작합니다
Figure 2. 마킹은 루트에서 시작합니다
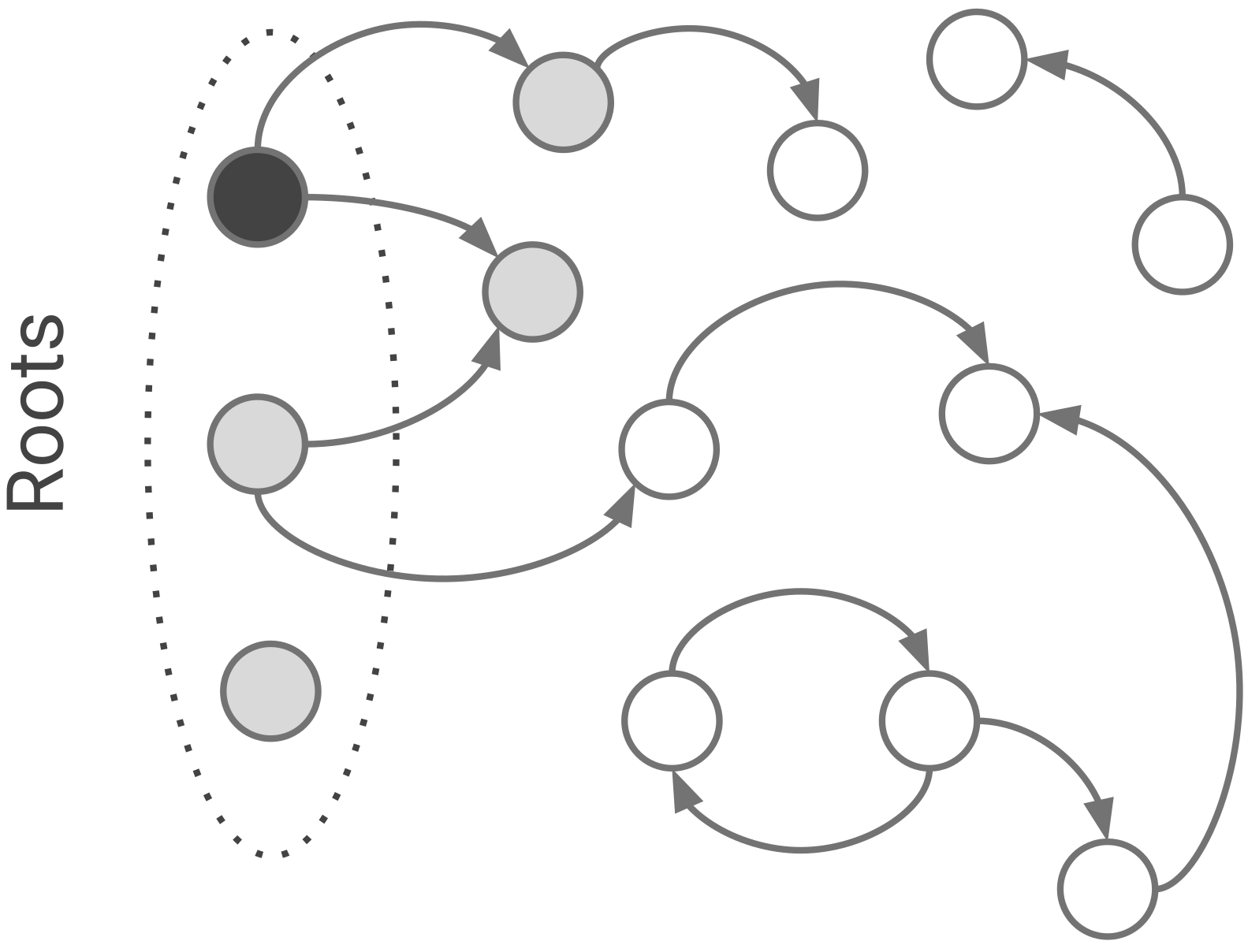 Figure 3. collector는 그것의 포인터들을 처리하면서 회색 객체를 검정으로 바꿉니다
Figure 3. collector는 그것의 포인터들을 처리하면서 회색 객체를 검정으로 바꿉니다
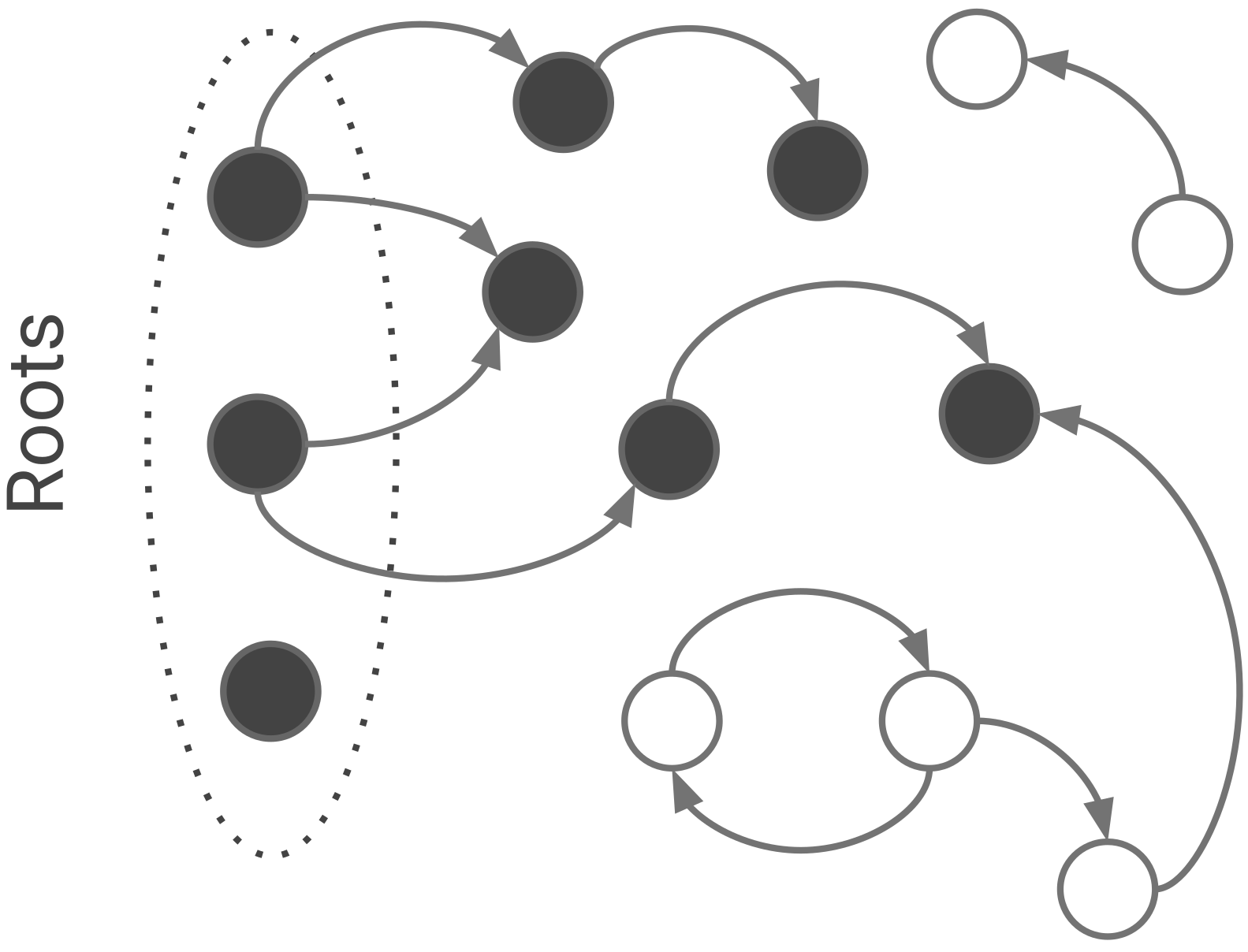 Figure 4. 마킹을 모두 마친 후의 모습
Figure 4. 마킹을 모두 마친 후의 모습
위에서 설명한 마킹 알고리즘이 진행되는 동안에는 어플리케이션 실행이 잠시 중단돼야 한다는 것에 주목해야 합니다. 만약 마킹 중에 어플리케이션이 계속 실행된다면, 그래프가 변경될 수 있을 것이고 결국 활성 객체를 collector가 수집해버릴 수도 있습니다.
마킹에 의한 중단 줄이기
대량의 heap의 경우 마킹이 한 번 실행되면 수백 밀리초를 소모하게 됩니다.

이렇게 오랜 시간 어플리케이션이 중단되는 것은 어플리케이션을 둔하게 만들고 유저 경험(UX)을 안 좋게 합니다. 2011년 V8은 stop-the-world 마킹에서 점진적인(incremental) 마킹으로 전환했습니다. 점진적 마킹을 수행하는 동안 garbage collector는 마킹 작업을 더 작은 덩어리들(chunks)로 쪼개고 그들 사이사이에 어플리케이션이 실행될 수 있도록 합니다:

garbage collector는 어플리케이션에 의한 할당 비율과 일치시키기 위해 각 덩어리에서 얼마나 마킹을 수행할 것인가를 선택합니다. 일반적으로 어플리케이션의 반응성이 상당히 향상됩니다. 메모리 부족으로 인해 대량의 heap들에 대해서는 collector가 할당을 유지하려고 시도할 때 여전히 오랜 시간 중단이 있을 수 있습니다.
점진적 마킹은 알아서 제공되지 않습니다. 어플리케이션은 garbage collector에게 객체 그래프를 변화시키는 모든 연산에 대해 알려야합니다.
V8은 다익스트라 스타일의 write-barrier를 이용해서 그 알림을 구현합니다. 자바스크립트에서 각각의 object.field = value 형식의 쓰기 연산 뒤에, V8은 이 write-barrier 코드를 삽입합니다:
// `object.field = value` 호출 후
write_barrier(object, field_offset, value) {
if (color(object) == black && color(value) == white) {
set_color(value, grey);
marking_worklist.push(value);
}
}
write-barrier는 검정 객체가 흰색 객체를 가리키지 못하도록 강제합니다. 이는 strong tri-color invariant라고도 불리는데, 어플리케이션이 garbage collector로부터 활성 객체를 숨길 수 없도록 보장해줍니다. 따라서 마킹 후에 모든 흰색 객체는 확실하게 도달될 수 없고, 안전하게 수집될 수 있는 것입니다.
점진적 마킹은 이전의 블로그 포스트에서 설명한 idle time garbage collection 스케쥴링과 잘 통합됩니다. 크롬의 Blink 테스크 스케쥴러는 jank 없이 메인 쓰레드가 노는 시간(idle time) 동안에 약간의 점진적인 마킹 단계들을 스케쥴할 수 있습니다. 이 최적화는 노는 시간이 사용될 수 있는 경우에 효과적입니다.
write-barrier 비용 때문에, 점진적인 마킹은 어플리케이션의 처리량을 감소시킬 수도 있습니다. 추가적인 워커 쓰레드를 만듦으로써, 처리량과 중단 시간을 모두 개선시키는 것이 가능합니다. 워커 쓰레드에서 마킹을 진행하는 두 가지 방법이 있습니다: parallel 마킹과 concurrent 마킹.
Parallel 마킹은 메인 쓰레드와 워커 쓰레드에서 일어납니다. parallel 마킹 동안에 어플리케이션은 중단됩니다. 이는 stop-the-world 마킹의 멀티 쓰레드 버전입니다:

Concurrent 마킹은 주로 워커 쓰레드에서 일어납니다. concurrent 마킹이 진행되는 동안 어플리케이션은 계속해서 실행될 수 있습니다.

다음에 나오는 두 섹션에서 우리가 어떻게 V8에 parallel과 concurrent 마킹에 대한 지원을 추가했는지 설명합니다.
Parallel 마킹
parallel 마킹 동안에 어플리케이션이 함께 실행되지 않을 수 있다고 가정할 수 있습니다. 이렇게 되면 객체 그래프는 정적이고 바뀌지 않을 것이기 때문에, 구현이 상당히 간단해집니다. parallel로 객체 그래프를 마킹하기 위해서는, garbage collector 자료 구조를 thread-safe하게 만들 필요가 있고, 쓰레드 간에 마킹 결과도 효율적으로 공유할 방법도 찾아야 합니다. 아래의 다이어그램이 parallel 마킹에 관련된 자료구조들을 보여줍니다. 화살표는 데이터 흐름을 나타냅니다. 간단하게 하기 위해, heap defragmentation(조각 모으기)을 위해 필요한 자료구조들은 생략했습니다.
 Figure 5. parallel 마킹을 위한 자료구조
Figure 5. parallel 마킹을 위한 자료구조
쓰레드들은 객체 그래프를 읽기만 할 뿐 바꾸지는 않는다는 것을 주목해야 합니다. 해당 객체의 mark-bit들과 마킹 worklist는 읽기/쓰기 접근이 가능해야만 합니다.
마킹 worklist와 일감 뺏기
마킹 worklist의 구현은 성능 면에서 중요하고, 또 빠른 쓰레드 로컬 성능과 일감이 부족한 경우 얼마 만큼의 일이 다른 쓰레드들에게 분배될 수 있는가를 균형 맞춥니다. trade-off space에서의 극단적인 측면들은 (a)모든 객체가 공유될 가능성이 있으므로, 최적의 공유를 위한 완전한 concurrent 자료구조를 사용하는 것과 (b)객체가 공유될 수 없는 곳에서 쓰레드 로컬 산출물을 위한 최적화를 하며 완전한 쓰레드 로컬 자료구조를 사용하는 것입니다. Figure 6.은 쓰레드 로컬 삽입과 삭제 세그먼트(segments)에 기반한 마킹 worklist를 이용하여 V8이 어떻게 그들의 요구를 균등하게 처리하는지 보여줍니다. 한 세그먼트가 꽉 차게 되면, 공유하는 전역 pull(뺏기가 가능한)에 공표(publish) 됩니다. 이런 방식으로 V8은 마킹 쓰레드들이 지역적으로, 가능한 오랫동안 동기화 없이 동작할 수 있도록 해주고, 완전히 자신의 로컬 세그먼트를 drained한 다른 쓰레드가 굶주리는 동안 단일 쓰레드가 객체들의 새로운 서브 그래프에 도달한 경우들도 처리할 수 있도록 해줍니다.
 Figure 6. 마킹 worklist
Figure 6. 마킹 worklist
Concurrent 마킹
concurrent 마킹은 워커 쓰레드들이 heap에 있는 객체들을 방문하는 동안, 자바스크립트가 메인 쓰레드에서 실행될 수 있도록 해줍니다. 이로 인해 많은 잠재적 데이터 레이스가 열립니다. 예를 들어, 자바스크립트는 워커 쓰레드가 어떤 객체의 필드를 읽는 동안 동시에 그 객체의 필드에 값을 쓰고 있을 수도 있습니다. 이런 데이터 레이스는 garbage collector가 활성 객체를 수집할지말지 혼란스럽게 하거나, 원시 값과 포인터를 혼동하도록 혼란스럽게 합니다.
객체 그래프를 변경시키는 메인 쓰레드에서의 각 연산은 데이터 레이스의 잠재적 원인입니다. V8은 여러 객체 레이아웃 최적화를 통한 높은 성능의 엔진이기 때문에, 잠재적 데이터 레이스의 소스들의 리스트는 약간 깁니다. 이들은 높은 수준의 breakdown 입니다:
- 객체 할당
- 객체 필드에 쓰기
- 객체 레이아웃 변경
- 스냅샷 디-시리얼라이즈하기
- 함수 비최적화 동안 실체화하기
- 젊은 세대의 garbage collection 동안 evacuation
- 코드 패치
이러한 연산들에 있어 메인 쓰레드는 워커 쓰레드들과 동기화를 해야합니다. 동기화의 비용과 복잡도는 연산에 의존합니다. 대부분의 연산들은 원자 단위 메모리 접근의 가벼운 동기화를 허용하지만, 몇몇 연산들은 객체에 대해 독점적인 접근을 요구합니다. 다음 서브 섹션들에서 몇몇 흥미로운 경우들을 강조하겠습니다.
쓰기 barrier
객체 필드 값 쓰기에 의한 데이터 레이스는 쓰기 연산을 완화된 원자 단위(relaxed atomic write) 쓰기로 변경함으로써, 쓰기 barrier를 약간 수정함으로써 해결될 수 있습니다:
// atomic_relaxed_write(&object.field, value); 호출 후
write_barrier(object, field_offset, value) {
if (color(value) == white && atomic_color_transition(value, white, grey)) {
marking_worklist.push(value);
}
}
이전에 사용한 쓰기 barrier와 비교해보세요:
// `object.field = value`; 후
write_barrier(object, field_offset, value) {
if (color(object) == black && color(value) == white) {
set_color(value, grey);
marking_worklist.push(value);
}
}
두 가지 변화가 있습니다:
- 소스 객체의 색깔 체크(
color(object) === black)가 없어졌습니다. - 흰색에서 회색으로 value의 색 변화가 원자 단위로 실행됩니다.
소스 객체의 색깔 확인 없이는 쓰기 barrier가 더욱 보수적이게 됩니다. 즉, 실제로 접근할 수 없는 객체들에 대해서도 활성 객체로 마킹할 수도 있습니다. 쓰기 연산과 쓰기 barrier 사이에 필요하게 되는 값 비싼 메모리 fence를 피하기 위해 확인을 제거하였습니다:
atomic_relaxed_write(&object.field, value);
memory_fence();
write_barrier(object, field_offset, value);
메모리 fence 없이, 객체 색깔을 로드하는 연산은 쓰기 연산보다 앞으로 재배치 될 수 있습니다. 만약 재배치를 막지 않으면, 쓰기 barrier는 회색 객체를 관측하게 되고, bail out 할 수 있습니다. 워커 쓰레드가 새 값을 보지 않고 해당 객체를 마킹합니다. 다익스트라 등에 의해 제시된 오리지널 쓰기 barrier는 객체 색깔을 확인하지 않습니다. 그들은 단순하게 하기 위해 그랬지만, 우리는 정확성이 요구됩니다.
구제 worklist
코드 패칭과 같은 몇몇 연산들은 객체에 대한 독점적인 접근은 필요로 합니다. 초기에 객체 별 락을 피하기로 결정했습니다. 왜냐하면 우선순위가 도치되는 문제를 야기할 수도 있기 때문입니다. 메인 쓰레드가 객체 락을 유지하면서 예정되지 않은 워커 쓰레드를 기다려야만 합니다. 객체를 락하는 것 대신에, 워커 쓰레드가 그 객체를 방문하는 것으로부터 구제되도록 하였습니다. 워커 쓰레드는 메인쓰레드만이 처리할 수 있는 구제 worklist에 해당 객체를 밀어넣습니다:
 Figure 7. 구제 worklist
Figure 7. 구제 worklist
워커 쓰레드는 최적화된 코드 객체들, hidden class 그리고 weak collection들을 구제합니다. 왜냐하면 그들을 방문하는 것은 락킹이나 비싼 동기화 프로토콜을 요구하기 때문입니다. 돌이켜보면, 구제 worklist는 점진적 개발에서 좋다는 것이 드러났습니다. 우리는 모든 객체 타입들을 구제하면서 워커 쓰레드들을 구현하였습니다. 그리고 하나씩 concurrency를 추가했습니다.
객체 레이아웃 변화
객체 필드는 세 종류의 값들을 저장할 수 있습니다: 태그된 포인터, 태그된 작은 정수(Smi), unbox된 플로팅 포인트 숫자와 같은 태그되지 않은 값. 포인터 태깅(Pointer tagging)은 잘 알려진 기술입니다. 그것은 unboxed된 정수를 효율적으로 표현할 수 있게 합니다. V8에서 태그된 값의 the least significant bit는 그것이 포인터인지 정수인지를 가리킵니다. 이것은 포인터들은 word-aligned라는 사실에 기인합니다. 한 필드의 태그 여부 정보는 그 객체의 hidden class에 저장됩니다.
V8에서의 몇몇 연산은 객체 필드를 태그된 것에서 태그되지 않은 것으로, 혹은 그 반대로 해당 객체를 다른 hidden class로 전이함으로써 변경합니다. 그러한 객체 레이아웃 변경은 concurrent 마킹에 있어 안전하지 않습니다. 만약 워커 쓰레드가 이전의 hidden class를 통해 객체를 방문하고 있는 도중에 변화가 발생한다면, 두 가지의 버그가 발생할 수 있습니다. 첫 째로, 워커는 그것을 태그되지 않은 값이라 생각하며 포인터를 잃어버릴 수도 있습니다. 쓰기 barrier는 이러한 종류의 버그를 방지합니다. 둘 째로, 워커는 태그되지 않은 값을 포인터라고 다루고, 그것을 역참조할 수도 있습니다. 일반적으로 이것은 타당하지 않은 메모리 접근을 야기하여 프로그램 충돌을 발생시킵니다. 이 경우를 처리하기 위해서, 해당 객체의 mark-bit의 동기화를 맞춰주는 스냅샷 프로토콜을 사용합니다. 이 프로토콜은 두 녀석들과 관련이 있습니다: 객체 필드를 태그된 것에서 태그 되지 않은 것으로 변경하는 메인 쓰레드와 그 객체를 방문하는 워커 쓰레드. 필드를 변경하기 전에, 메인 쓰레드는 객체는 검정으로 마킹되었음을 보장하고, 추후에 방문하기 위해 구제 worklist에 push합니다:
atomic_color_transition(object, white, grey);
if (atomic_color_transition(object, grey, black)) {
// The object will be revisited on the main thread during draining
// of the bailout worklist.
bailout_worklist.push(object);
}
unsafe_object_layout_change(object);
아래 코드 조각에서 보여지는 것처럼, 워커 쓰레드는 먼저 객체의 hidden class를 불러오고 atomic relaxed load operations을 이용하여 hidden class에 명시된 객체의 모든 포인터들을 스냅샷 찍습니다. 그리고 원자 단위의 비교/교체 연산을 이용하여 객체를 검정색으로 마킹하기 시작합니다. 마킹이 성공적으로 끝났다면, 이는 hidden class와 스냅샷이 일치함을 의미합니다. 메인 쓰레드는 객체의 레이아웃이 변경되기 전에 검정으로 마킹했기 때문입니다.
snapshot = [];
hidden_class = atomic_relaxed_load(&object.hidden_class);
for (field_offset in pointer_field_offsets(hidden_class)) {
pointer = atomic_relaxed_load(object + field_offset);
snapshot.add(field_offset, pointer);
}
if (atomic_color_transition(object, grey, black)) {
visit_pointers(snapshot);
}
안전하지 않은 레이아웃 변경을 겪고 있는 흰색 객체는 메인 쓰레드에서 마킹 되어야만 한다는 것에 주목하세요. 안전하지 않은 레이아웃 변경은 상대적으로 드뭅니다. 따라서 실제 어플리케이션에서는 큰 영향을 미치지 않습니다.
모두 모아서
concurrent 마킹을 존재하는 점진적인 마킹 infrastructure로 통합했습니다. 메인 쓰레드는 루트를 스캔함으로써 마킹을 시작하고, 마킹 worklist를 채웁니다. 그 후, concurrent 마킹 업무를 워커 쓰레드들에게 게시합니다. 워커 쓰레드들은 메인 쓰레드를 도와 마킹 worklist를 소모시킴으로써 마킹 처리를 더욱 빠르게 합니다. 가끔 메인 쓰레드는 구제 worklist와 마킹 worklist를 처리함으로써 마킹에 참여합니다. 마킹 worklist가 비어 있게 되면, 메인 쓰레드는 garbage collection을 완료합니다. 완료하는 동안에 메인 쓰레드는 루트를 다시 스캔하고 추가적인 흰색 객체들을 발견할 수도 있습니다. 이 객체들은 워커 쓰레드들의 도움으로 parallel하게 마킹됩니다.

결과
실세계 벤치마킹 프레임워크는 모바일과 데스크탑 각각에서 하나의 garbage collection 주기 동안 약 65%, 70%의 메인 쓰레드의 마킹 시간의 감소를 보여줍니다.

Concurrent 마킹은 Node.js에서 garbage collection jank 역시 감소시킵니다. Node.js는 유휴 시간 garbage collection 스케쥴링을 절대 구현하지 않았고, 그래서 non-jank-critical 단계에서 마킹 시간을 감출 수 없기 때문에 이는 특히 중요합니다. Concurrent marking은 Node.js v10에 실려있습니다.